overleaf skabelonsgalleriLaTeX templates and examples — Recent
Opdag LaTeX skabeloner og eksempler til at hjælpe med alt fra at skrive en artikel til at bruge en specifik LaTeX pakke.

This is a simple report template with the UCT logo. Feel free to use/modify it to suit your needs. Variables that need to be altered have been commented to make modifications easier. For example if you need to change the university logo, look for the comment '% University Logo' in main.tex and then make appropriate modifications in that line. A Table of Contents and a bibliography have also been implemented. To add entries to your bibliography, simply edit biblist.bib in the root folder and then use the '\cite{...}' command in main.tex. The Table of Contents will be updated automatically. I hope that you find this template both visually appealing and useful. - Linus

Template for AFIT thesis defense presentations using standard LaTeX \chapter and \section commands, rather than Beamer environments. Distribution Statement A. Approved for public release: distribution is unlimited.

Pakiet rotating umożliwia dowolny obrót różnych obiektów w dokumencie: tekstu, tabel i obrazów. Czytaj więcej na: http://pakietomat.wordpress.com/

This is a skeleton file demonstrating the use of the IEEEtran.cls style with an IEEE journal paper, and with example bibliography files included. These bibliography files are includes to provide one example of how to set up a bibliography for your IEEE paper. For more information on using bibtex for references in your IEEE journal papers, see this FAQ. IEEEtran.cls version: 1.8b

Modelo de avaliações do curso de tecnologia em sistemas para a internet do câmpus de toledo-PR. This template was originally published on ShareLaTeX and subsequently moved to Overleaf in October 2019.

La dinámica de los precios de los metales no sólo son altamente relevantes para los consumidores debido a sus amplios usos en diversas industrias, sino también para una serie de países productores. Para estos países, la obtención de exportación son a menudo la principal fuente de ingresos. Por lo tanto, el examen preciso de los precios de los metales, su largo y corto plazo el comportamiento cíclico, y su co-movimiento es esencial para fines de cepillado y de previsión económica. Este estudio examina la dinámica de 20 series de precios mensual de una variedad de productos minerales durante los últimos 100 años. En comparación con los primeros estudios, que están restringidos ya sea a la historia de los últimos 50-60 años o se basan en los datos de frecuencia anual, este conjunto de datos es una gran ventaja. Co-movimiento, a corto plazo los ciclos y los ciclos de súper se analizaron por medio de métodos estadísticos comunes y se comparan con los resultados en la literatura. Los resultados sugieren que los precios del metal no necesariamente siguen patrones similares. Aunque un patrón común es discernible dentro de ciertos grupos de metales, tales como metales preciosos y metales no ferrosos, otros grupos de metal como los metales y aleaciones de acero eléctrico puede mostrar muy diferentes dinámica de los precios con respecto a los ciclos de co-movimiento y los precios a corto plazo. Sin embargo, los resultados en la literatura en relación con los ciclos super (1910-1938, 1938-1968, 1968-1996, 1996-en curso) puede normalmente ser confirmado por los datos que figuran en este estudio.

A gussied-up version of the UA Astro thesis template previously passed down for generations via email

Smallest possible LaTeX document for teaching LaTeX
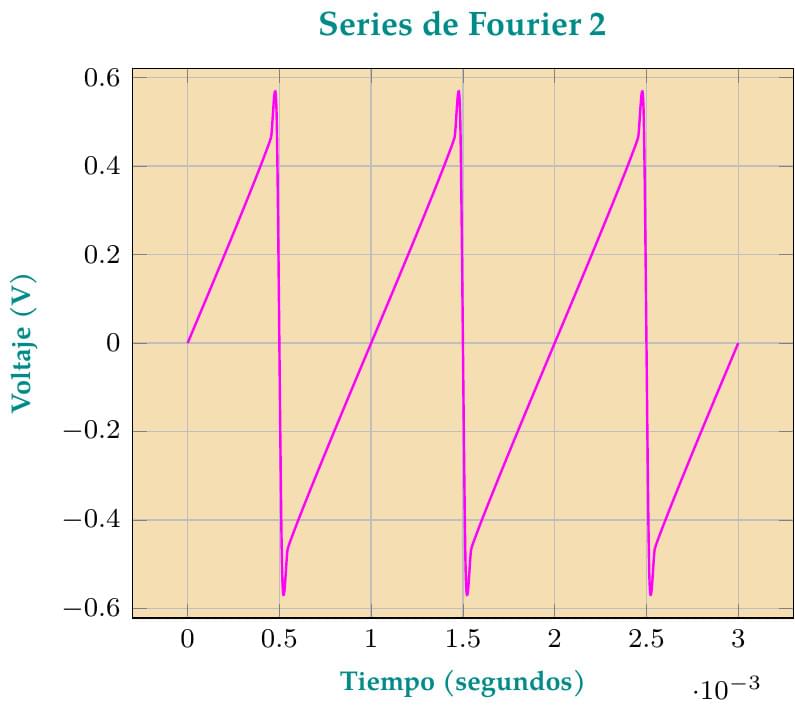
Este gráfico es una mejora, aprovechando el uso de GNUPLOT, de la primera versión que fue publicada por Overleaf. En este caso, la onda de "diente de sierra" es definida según lo indicado en el texto "Mathematical Handbook of Formulas and Tables" de la serie "Schaum's Outlines", de la editorial McGraw Hill, Quinta Edición, página 145. Para mayor precisión, son sumados los 100 primeros términos de la Serie de Fourier, lo cual no afecta grandemente el tiempo de compilación en los servidores de Overleaf.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.